前言
这篇论文被BWCCA 2018收录,链接。这篇论文提出了基于符号执行,结合对宿主源程序的结构特点分析,找到潜在的漏洞可插入点,构建漏洞样本的自动化生成技术。目标是给目前发展迅速的Fuzzing技术(灰盒测试)提供基准测试集,助力漏洞挖掘技术的发展。论文采用开源项目作为测试目标,并使用一定的工具进行数据集的验证。
论文虽然提出了一个较为理想的方案,但是在具体执行的时候含糊其辞,有些地方可能因为操作比较困难就省略了,得到的结果也不是特别理想。但是采用符号执行进行潜在漏洞插入点的探索是值得借鉴的。
必要性与目标
-
必要性
目前基准测试集的来源基本上包括两个方面:一个是以NIST(SARD)为首的各大漏洞数据集,这些数据集虽然总量上看上去也不小,但是很多单个类型的数量较少,且因为简化的缘故很多程序仅仅保留漏洞的基本特征,缺乏真实性。第二个就是一些最近公开的漏洞软件集合,这种数据集漏洞数量堪忧。而且很多简单的、浅显的漏洞在这些软件中已经很少出现,Fuzzing测试越发艰难。 TaintScope和AFLFast 统一、标准的测试集是有必要的,帮助分析Fuzzing框架的优劣。自动生成的样本应该具有以下几个特点:
- 数量大、类型多
- 能够覆盖程序的整个生命周期
- 尽可能与输入数据联系在一起
- 可触发、拥有PoC样例(这个PoC不太清楚啥意思,看论文应该是P代表程序的意思,C应该Crash)
- 不改变程序的正常功能或者原语义
- 尽可能接近真实漏洞环境
-
目标
- 根据符号执行,分析给出的宿主源程序
- 将漏洞(此处应该是漏洞模板)注入符合特殊条件的位置
- 使用ASAN (Address Sanitizer)进行内存泄露情况的测试
过程

-
遍历分支
使用符号执行工具KLEE得到遍历每一个分支的INPUTS
-
标记潜在漏洞位置
论文认为暂时没有简单方式创建逻辑上的漏洞,所以仅仅关注三种漏洞:缓冲区溢出、整数溢出、数组边界溢出。
- 缓冲区溢出
- get、fgets等无限制的读取函数
- read、scanf等函数调用时,size没有经过验证
- 内存操纵函数比如strncpy、memcpy
- 整数溢出
-
有符号和无符号进行合并时
-
整数扩展
一个典型例子是

-
- 数组边界溢出
- 参数检查
- 循环边界检查不正确
- 循环边界由用户控制
此过程分为:
-
找敏感函数
-
找条件语句
-
找读写函数

-
插入信息采集函数
用于采集在程序运行时潜在漏洞点产生的信息,包括函数参数、涉及条件语句的变量、循环边界、输入变量等等。PS:目前不知道这个函数怎么实现的,动态分析??
- 缓冲区溢出
-
注入
-
常规的改变敏感函数的变量,构造缓冲区溢出
-
删除或者弱化条件语句的条件
-
调整循环语句边界
例子

-
-
PoC验证
使用ASAN工具,这是一个用于内存泄漏检测的工具
-
评估
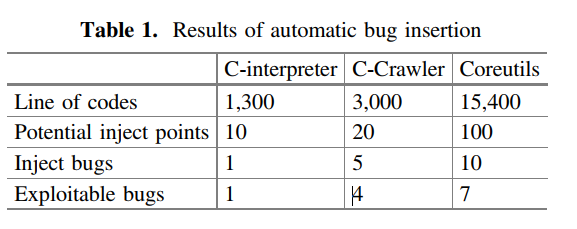
并没有和其他技术生成的测试集进行对比。

总结
虽然这篇论文采用符号执行进行对潜在漏洞位置的探索,但是在流程中符号执行几乎没有发挥作用,这很遗憾。