前言
这学期选了一门《Linux内核》的交叉选修课程,总共做了5个lab实验,于是在此期末之际,我写下一些记录便于以后参考。具体的代码以及实验报告我都在github上列了出来:https://github.com/Tongzhixin/Linux_Kernel_Lab。
这里只是简单说一些。
踩坑
所做的实验除了第二个外都是编写linux模块。
模块编程试炼
这一份代码中,包含了proc文件的创建,权限,写操作,读操作等等,另外linux5.6版本以后的file_operations结构改了,特别需要注意。
#define BUF_SIZE 100
char global_buffer[BUF_SIZE]; //创建全局数组
#define BASE_DIR_NAME "hello_proc" // 定义文件夹名称
#define FILE_NAME "hello" // 定义文件名称
static struct proc_dir_entry *file_entry; // 文件句柄
static struct proc_dir_entry *dir_entry;// 文件夹句柄
static int hello_proc_show(struct seq_file *m, void *v) {
seq_printf(m, "Hello proc!\n");
seq_printf(m, "global_buffer is %s\n", global_buffer);// 展示写入的内容
return 0;
}
static int hello_proc_open(struct inode *inode, struct file *file) {
return single_open(file, hello_proc_show, NULL);
}
// write函数
static ssize_t hello_proc_write(struct file *file, const char __user *buffer, size_t count, loff_t *f_pos){
int len;
if(count<BUF_SIZE)len=count; // 比较大小,取小的一个
else len = BUF_SIZE;
copy_from_user(global_buffer, buffer, len);// 将写入的缓冲区内容拷贝给global_buffer
global_buffer[len-1]='\0'; // 增加结束符号
return len;
}
static const struct file_operations fops={
.owner =THIS_MODULE,
.read = seq_read,
.open = hello_proc_open,
.write = hello_proc_write,
.llseek = seq_lseek,
.release = single_release,
};
static int __init homework4_init(void)
{
printk(KERN_INFO "homework4 init()!!");
dir_entry = proc_mkdir(BASE_DIR_NAME, NULL);
// 文件夹创建
if(!dir_entry){
printk(KERN_INFO "proc create %s dir failed\n", BASE_DIR_NAME);
return -1;
}
// 文件创建
file_entry = proc_create(FILE_NAME, 0777, dir_entry, &fops);
if(!file_entry)
return -1;
else{
printk(KERN_INFO "created!");
return 0;
}
}
static void __exit homework4_exit(void)
{
printk(KERN_INFO "finish homework4 exit()!!");
// 退出之后要移除相应的文件,否则在正常文件系统中无法移除
remove_proc_entry(FILE_NAME, dir_entry);
remove_proc_entry(BASE_DIR_NAME,NULL);
}
module_init(homework4_init);
module_exit(homework4_exit);
进程管理
主要是对内核的源码进行更改然后编译,此次是修改进程控制块,往里面添加一个数据结构,然后在每次进程创建时,改变这个值,并在proc文件系统中创建一个可读可写的文件,能够显示出这个数据结构的值。详情可见仓库中的报告。
主要的难点在于读源码以及频繁的编译和运行,很容易把系统搞挂。
内存管理
这是我花费最长,付出精力最多的一个实验,这个实验让我对内存中的地址管理有了深刻的认识,对页表的转换,虚拟地址与物理地址的转换都有了更深刻的认识。
整个实验可以分为四部分内容:
- 创建proc文件并收集写入的内容,作为之后触发函数的条件
- 打印当前进程的所有虚拟地址
- 将虚拟地址转化为物理地址
- 向虚拟地址中写入一个值
tips & questions
-
内核地址空间采用线性映射和页表转换,一定会有线性映射,但是映射后一般会建立相应的页表映射。
-
获取内核态的虚拟地址,只需要将相应物理地址使用
phys_to_vir即可获取对应的虚拟地址,也可以先获取相应page的虚拟地址(使用page_address()函数),然后与page_offset进行|运算。 -
获取物理硬件地址:如果虚拟地址是内核态,直接
vir_to_phys即可,如果虚拟地址用户态,则需要进行针对性的页表转换,获取到page,然后通过page_to_phys(page)函数获取物理地址,然后进行与或操作。page_addr = page_to_phys(page) & PAGE_MASK; page_offset = addr & ~PAGE_MASK; -
pte_offset_map与pte_offset_kernel的区别主要在于
-
疑问:使用
pte_val(*pte)获取页表框,与pte_page(*pte)效果不相同,使用pte_page能够获得正确的page,并且使用page获取物理地址。下文是我写的相关的对比代码,以及输出截图。if (!(pte = pte_offset_kernel(pmd, addr))) { printk(KERN_INFO "1 level error \n"); return 0; } if (!(page = pte_page(*pte))) return 0; page_addr = page_to_phys(page) & PAGE_MASK; page_offset = addr & ~PAGE_MASK; printk(KERN_INFO "the page_addr %lx \n", page_addr); printk(KERN_INFO "the page_offset %lx \n", page_offset); physical_page_addr = page_addr | page_offset; physical_page_addr1 = phys_to_virt(physical_page_addr); unsigned long physical_page_addr2; unsigned long physical_page_addr21; page_addr1 = pte_val(*pte) & PAGE_MASK; page_offset1 = addr & ~PAGE_MASK; printk(KERN_INFO "the page_addr1 %lx \n", page_addr1); printk(KERN_INFO "the page_offset1 %lx \n", page_offset1); physical_page_addr2 = page_addr1 | page_offset1; physical_page_addr21 = phys_to_virt(physical_page_addr2); printk(KERN_INFO "the physical_page_addr is %lx \n", physical_page_addr); printk(KERN_INFO "the physical_page_addr2 is %lx \n", physical_page_addr2); printk(KERN_INFO "the physical_page_addr1 is %lx \n", physical_page_addr1); printk(KERN_INFO "the physical_page_addr21 is %lx \n", physical_page_addr21);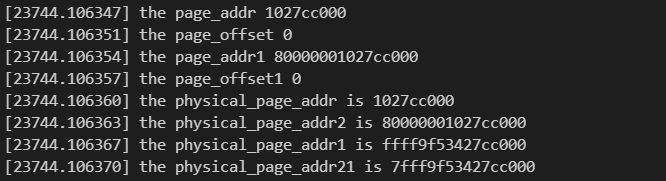
参考链接:
- https://zhuanlan.zhihu.com/p/146477822
- http://faculty.washington.edu/wlloyd/courses/tcss422_f2018/assignments/TCSS422_f2018_A3.pdf
- https://www.cnblogs.com/alantu2018/p/8459336.html
- https://github.com/ljrcore/linuxmooc/blob/master/%E7%B2%BE%E5%BD%A9%E6%96%87%E7%AB%A0/%E6%96%B0%E6%89%8B%E4%B8%8A%E8%B7%AF%EF%BC%9ALinux%E5%86%85%E6%A0%B8%E4%B9%8B%E6%B5%85%E8%B0%88%E5%86%85%E5%AD%98%E5%AF%BB%E5%9D%80.md
- https://www.cnblogs.com/emperor_zark/archive/2013/03/15/linux_page_1.html
- https://blog.csdn.net/u013920085/article/details/50856217
- https://zhuanlan.zhihu.com/p/66794639
实现动态修改系统调用
- 寻找系统调用表内存地址
- 系统调用表:在 Linux 系统中,每个系统调用都有相应的系统调用号作为唯一的标识,内核维护一张系统调用表:
sys_call_table。在 64 位系统中,sys_call_table的定义在entry/syscall_64.c,可以把sys_call_table看作一个数组,索引为系统调用号,值为系统调用函数的起始地址。 - 通过网上查资料,获取调用表地址,有多种方法,包括通过
/boot/System.map获取、通过/proc/kallsyms获取、通过遍历内存搜索获取、调用kallsyms_lookup_name函数获取。其中前两种方式都是对文件内容进行过滤,而且第一种已经失效。 - 内存遍历获取调用表起始地址:内核内存空间的起始地址
PAGE_OFFSET变量和sys_close系统调用在内核模块中是可见的。系统调用号在同一ABI(x86与x64属于不同ABI)中是高度后向兼容的,可以直接引用(如__NR_close)。我们可以从内核空间起始地址开始,把每一个指针大小的内存假设成sys_call_table的地址,并用__NR_close索引去访问它的成员,如果这个值与sys_close的地址相同的话,就可以认为找到了sys_call_table的地址。在内核版本5.3之后sys_close被更换为ksys_close,这点需要注意。 kallsyms_lookup_name是最简单的一种方法,只需要调用该函数,参数为sys_call_table即可返回系统调用表的起始位置,非常方便,本次也使用这种方式进行系统调用表的获取。
- 系统调用表:在 Linux 系统中,每个系统调用都有相应的系统调用号作为唯一的标识,内核维护一张系统调用表:
- 自定义系统调用函数
- 自定义的系统调用函数需要覆盖原有的系统调用函数,且需要保证正常调用能够运行,所以需要在自定义系统调用函数中调用原有的系统调用函数。
- 查看所拦截的系统调用函数的参数,并依照其设置自定义调用函数的参数。
- 关闭与开启写保护
CR0是系统内的控制寄存器之一。控制寄存器是一些特殊的寄存器,它们可以控制CPU的一些重要特性。CR0的第16位是写保护未即WP位(486系列之后),只要将这一位置0就可以禁用写保护,置1则可将其恢复。- 系统不允许修改系统调用表,在内存中设置了写保护,可以通过修改CR0寄存器的第16位进行禁用写保护。
- Linux 内核提供的接口
set_bit和clear_bit来操作比特。Linux5.0上直接调用write_cr0接口,能够顺利的写入CR0寄存器,而内核版本更新到Linux5.3以后,对CR0的修改进行了保护,所以这里需要自定义write_cr0的实现,直接从Linux5.0中把相关代码静态编译进入模块中。这样也可以绕过对CR0的保护。
感受
课程虽然是交叉选修,但是我仍然付出了很多精力在这个作业上面,授课老师也很认真地在讲解,更好的是这门课与操作系统在同一个学期,这样两者互补就很好,学到了很多知识。
但是我也发现了国内布置作业的一个弊端,助教给出的作业指导仍然不够详细,在进行内存管理的lab时,我找到了美国一所大学的cs相关课程的lab,跟我们的任务很相似,但是简单很多,他们仅仅要求打印每一个进程的虚拟地址块起点和终点的物理地址,但是他们的作业指导长达将近8页,对相关的知识点补充非常的详尽,我觉得这才应该是要求学生独立完成一个lab的前提条件。
另外,Linux内核博大精深,可玩性很高,很希望国内也能有很多人玩这么底层而不是整天只知道全栈开发、做业务、敛财这些事情。